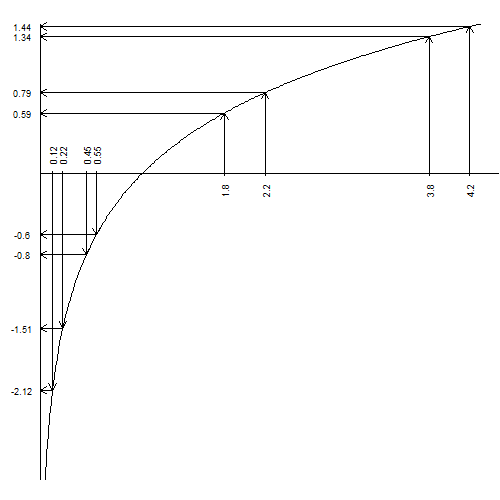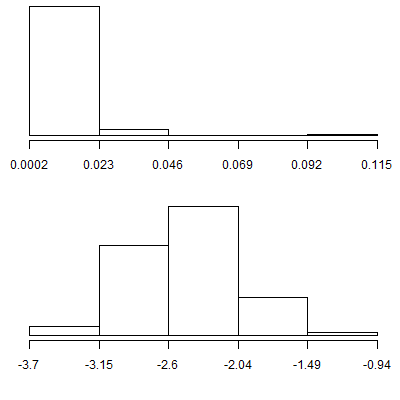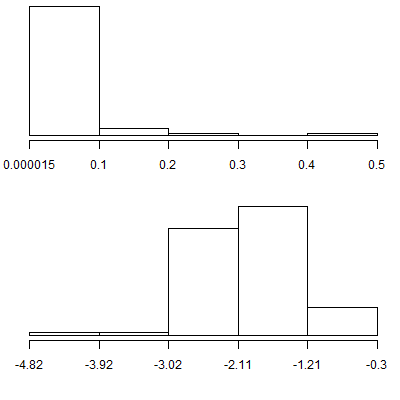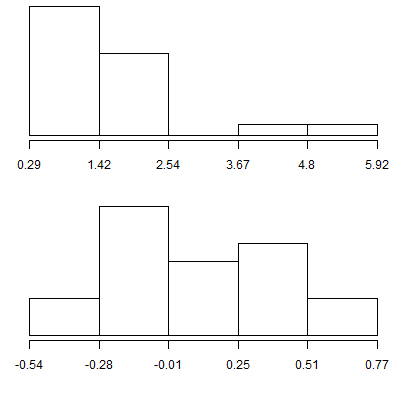[The Monthly Mean] September/October 2010--Unequal sample sizes? Don't worry!
The Monthly Mean is a newsletter with articles about Statistics with occasional forays into research ethics and evidence based medicine. I try to keep the articles non-technical, as far as that is possible in Statistics. The newsletter also includes links to interesting articles and websites. There is a very bad joke in every newsletter as well as a bit of personal news about me and my family.
Welcome to the Monthly Mean newsletter for September/October 2010. If you are having trouble reading this newsletter in your email system, please go to www.pmean.com/news/201009.html. If you are not yet subscribed to this newsletter, you can sign on at www.pmean.com/news. If you no longer wish to receive this newsletter, there is a link to unsubscribe at the bottom of this email. Here's a list of topics.
Lead article: Unequal sample sizes? Don't worry!
2. Is it ethical to exclude non-English speaking patients from a clinical trial?
3. When and why to log
4. Monthly Mean Article (peer reviewed): What is a pilot or feasibility study? A review of current practice and editorial policy
5. Monthly Mean Article (popular press): Lies, Damned Lies, and Medical Science
6. Monthly Mean Book: The Immortal Life of Henrietta Lacks
7. Monthly Mean Definition: What is the number needed to treat?
8. Monthly Mean Quote: All who drink of this remedy...
9. Monthly Mean Unsung Hero Award: John Hall
10. Monthly Mean Website: Advice on designing scientific posters
11. Nick News: Nicholas the arachnologist
12. Very bad joke: A SQL query goes into a bar...
13. Tell me what you think.
14. Upcoming statistics webinars
15. Join me on Facebook and LinkedIn
1. Unequal sample sizes? Don't worry!
A lot of people get really worried when they have unequal sample sizes--more observations in one group than in another. This is sometimes also called unbalanced data. In general this is much ado about nothing. The traditional approach to data analysis (t-test if there are two groups being compared or ANOVA if there are three or more groups being compared) works just fine with unequal sample sizes.
There are a few things to worry about. The formulas are a bit more complicated with unequal sample sizes, but that's hardly a serious consideration these days. Just let the computer figure things out.
The biggest thing to worry about when you have two groups with unequal sample sizes is that this can exacerbate the problem of unequal variances. So be sure and watch for this. With equal sample sizes, you can get a nice version of the t-test that adapts for unequal variances, but with unequal sample sizes, you have to make due with an approximation called the Satterthewaite test.
With three of more groups, another issue associated with unequal sample sizes or unbalanced data arises. Most post hoc tests comparing pairwise differences among the means (like the Tukey test) require equal sample sizes in each group. A commonly used approximation is to replace each sample size with the harmonic mean sample size and this provides a reasonable approximation as long as the sample sizes are not grossly unequal. The Bonferroni adjustment should get serious consideration here. It is simple to apply and works just as well with equal or unequal sample sizes.
Unbalanced data with two or more factors also creates some difficulties. Balanced data where each combination of the two factors has exactly the same number of observations is behave nicely. Almost as nice is data where the imbalance in one factor is perfectly preserved across the other factor. An example is where for the first level of Factor A, you have 20 and 10 observations in the two levels of Factor B, and for the second level of Factor B, you have 60 and 30 observations respectively, preserving the 2 to 1 imbalance. For both of these cases, Factors A and B are orthogonal, making it very easy to look at the effect of one factor adjusted for the other factor. With imbalanced data where the imbalance is disproportional (example 20 and 10 observations for the first level of Factor A and 50 and 10 observations for the second level of Factor A), there is more work to be done when you need to adjust one factor for the other. There are lots of things written about sequential and partial sums of squares in ANOVA and it gets really messy once you start putting interactions in the model.
Unequal sample sizes can actually be a good thing. If the cost of recruiting subjects is unequal, then it is cost effective to have unequal sample sizes. Suppose that it costs two thousand dollars to offer a new therapy to patients, but only twenty dollars to offer the standard therapy needed in the control group. You can get a lot more precision for the dollars spent by investing in a disproportionately larger number of the cheaper control patients. The actual ratio of patients should be proportional to the ratio of costs, meaning that in the above example with a 100-1 disparity in costs, the ideal ratio would be 10 control subjects for every treated subject.
I've written about unequal sample sizes a bit at my old website:
* http://www.childrensmercy.org/stats/weblog2004/UnequalSampleSizes.asp
* http://www.childrensmercy.org/stats/ask/unequal.asp
and this is an extension of those comments.Bottom line: don't let unequal sample sizes ruin your day.
2. Is it ethical to exclude non-English speaking patients from a clinical trial?
There was a debate in the IRB Forum about whether it was ethical to exclude non-English speaking patients from a research study. Most of the comments brought out the social justice issue, and other commented on the difficulty in assuring that informed consent is obtained in this population. There is an issue of scientific validity as well that needs to be considered.
There's a story I tell about dangerous extrapolations that I wrote up in the January 2009 newsletter.
* http://www.pmean.com/news/2009-01.html#11Now whenever you study one group of patients and try to generalize those results to a different group of patients, you are making a dangerous extrapolation. You can't necessarily trust adult data when treating children, for example.
So if non-English speakers are a target for the intervention being studied (not the only target, of course, but one of the targets), and they are not included in the study, it may create a dangerous extrapolation. It's not unlike the big fuss a decade ago when women were barred from entering many important clinical trials. It might make sense to have such an exclusion for prostate cancer, but there were exclusions in studies of conditions like heart disease that are major killers of women as well as men.
If a study excludes non-English speaking patients, and the results are relevant to this group, then the limited ability to extrapolate makes the study have less scientific merit. Sure, it has some value, but less value than if it included a broader base of patients.
It's not a deal breaker necessarily if you exclude a major subpopulation in your study. It depends a lot on the context. In particular, exploratory work early in the research process or proof of concept studies may not have extrapolation to broad population groups as a major goal. There is value in showing that an intervention can work at all, albeit under very idealized conditions. Pragmatic trials, on the other hand, would have a much harder time arguing against the exclusion of non-English speaking patients.
Just keep in mind, that in addition to all the social justice arguments that are being made that there is a scientific consideration as well. In some cases, the loss of greater generalizability might be enough to upset the cost/benefit ratio.
3. When and why to log
Possibly the most commonly used transformation in statistics is the log transformation. Instead of analyzing the outcome variable in a regression or ANOVA model, you transform the data by calculating the log of the outcome variable, and then analyze that variable. Mathematically, there is no reason to prefer a base 10 logarithm over a natural (base e) logarithm, though I find base 10 logarithms easier to interpret. A one unit shift in a base 10 logarithm is comparable to a shift of an order of magnitude in the original data. In many genetic studies, a base 2 logarithm is used. The interpretation here is also straightforward. A one unit change on a base 2 log scale corresponds to a doubling (or halving) on the original scale.
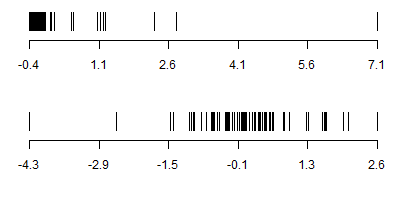
The log transformation is a non-linear transformation. That means that its effects are not proportional across the entire range of the data. The logarithm function squeezes together big data values (anything larger than 1) and stretches small values (anything smaller than 1). The bigger the data value, the more the squeezing and the smaller the data value the more the stretching. The graphs below shows this effect.
This graph shows the natural or base e logarithm to simplify the graphical presentation. Notice that 1.8 and 2.2, values that are 0.4 units apart, are only half as far apart on the log scale (0.59 and 0.79). Values even larger are squeezed even more. The gap between 3.8 and 4.2 shrinks to one fourth its size after a log transformation.
Small values are stretched by the log transformation and the smaller the value the more the stretching. Two values, 0.45 and 0.55, that are 0.1 units apart on the original scale are twice as far apart (-0.8 and -0.6) on the log transformed scale. Smaller values, 0.12 and 0.22, are stretched apart more than six times as wide by the log transform.
What are the potential benefits of a log transformation? I can show this with some data on metabolic ratios for three genetic subgroups.
The first benefit of the log transform is that it can sometimes change the distributional pattern of the data from a right skewed (positively skewed) distribution to something closer to the symmetric bell shaped curve associated with the normality assumptions needed for many statistical tests.
The upper and lower histograms shown here are the untransformed and log transformed metabolic ratios for patients with a rapid metabolizing genotype. Note that the log transformed data is more symmetric. The log transform can accomplish this because the values bunched up on the lower end are stretched apart more than the values at the upper end. The greater stretching in the left tail makes the data closer to symmetric.
Similarly, the distribution of metabolic ratios for moderate metabolizing genotype looks less skewed after a log tranformation.
Here are the histograms for untransformed and log transformed metabolic ratios for the poor metabolizing genotype. While the log transformation does not make the data perfectly symmetric and bell-shaped in all three cases, but it does seem to be much closer than the untransformed data.
Second, the log transformation can also sometimes reduce the impact of outliers, if (as is often the case) the outliers fall on the high end of the distribution. Two of the genotype groups in the data set illustrated above have serious problems with outliers.
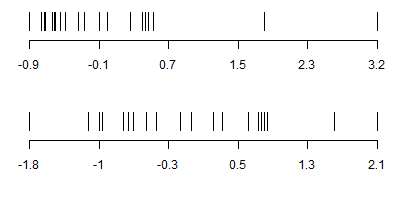
Again in this graph, the upper graph represents untransformed data and the lower graph represents log transformed data. The scale shown here is Z-scores and while a Z-score is not the best way to characterize outliers, it will serve just fine in this example. There is one outlier on the high end for the rapid metabolizing genotype group. It is 8.2 standard deviations above the mean. After the log transformation, all the data is within 3.4 standard deviations of the mean.
For the moderate metabolizing genotype, the same pattern emerges. There is a value in this group that is 7.1 standard deviations above average in the untransformed data. After a log transformation, there appears to be an outlier introduced on the low end, but at 4.3 standard deviations below the mean, it is much less extreme than the outlier on the high end in the untransformed data.
In the poor metabolizing genotype, there is only a slight outlier at 3.2 standard deviations above the mean, but even here the impact of this outlier is reduced after a log transformation.
Fourth, in many data sets the standard deviations for groups with smaller means tends to be smaller, the standard deviations for groups with larger means tends to be larger. A log transformation can sometime help stabilize the standard deviations.
Descriptive statistics for untransformed data
Rapid 0.0069 +/- 0.013
Moderate 0.028 +/- 0.028
Slow 1.58 +/- 1.37
Descriptive statistics for log transformed data
Rapid -2.4 +/- 0.44
Moderate -2.0 +/- 0.65
Slow 0.1 +/- 0.33The table above shows the mean and standard deviation for the three groups, first with untransformed data, then with log transformed data. Notice that the standard deviation for untransformed data in the slow metabolizing genotype group is five to ten times larger than the standard deviations in the other two groups. After a log transformation, the standard deviations are much closer to one another.
Fifth, the log transformation can simplify certain complex nonlinear relationships, especially relationships involving multiplicative rather than additive factors. There is a basic algebraic relationship involving logarithms that shows how logarithms can simplify mutliplicative relationships.
The logarithm effectively reduces a multiplication to an addition. There's a bad joke about this. After Noah's ark landed, he told the animals to go forth and multiply. The animals all dispersed with the exception of two snakes. Noah looked at them and said, "Didn't you heed my instructions to go forth and multiply?" The snakes replied, "We can't multiply; we're adders." So Noah took some wood from the ark and cut the pieces so as to fashion a small flat platform with four legs to support it. The adders could then multiply because they had a log table.
A log transformation isn't guaranteed to solve any of the problems mentioned above, and even if it does help, it may only help a little bit. Still, a log transformation should be considered as an early option to examine if one or more of the problems above appear to be of concern.
So when should you think about using a log transformation?
The first question to ask is whether your data includes zeros and/or negative numbers. You cannot use a log transformation unless all your data values are strictly greater than zero. Some people try to adapt the log transformation in this situation by adding a constant to each data value, but this inserts an extra element of arbitrariness to your data analaysis.
The second question to ask is if there is evidence that your data is skewed to the right. A histogram, a normal probability plot, or a boxplot will all give you an indication of this. Data that has a firm lower bound at zero and no obvious upper bound will often be skewed right. Right skewness can appear because you can't get outliers on the left tail because of this firm bound, but you can get outliers on the right tail. Log transformations make the most sense for data that are skewed right, but this is not an absolute requirement.
The third question to ask is whether the data covers a broad range. Typically, you need to see at least a three fold ratio between the largest and smallest data values--anything less than this and a log transformation is unlikely to have a major impact.
Finally, ask yourself if there are any existing precedents to use a log transformation for this type of data. You don�t have to have a precedent, but as the saying goes, "there�s safety in numbers."
There are other considerations, but these are the major ones that you should examine first.
Much of the material for this question was updated from two webpages from my old website:
* http://www.childrensmercy.org/stats/07/WhenToLog.asp
* http://www.childrensmercy.org/stats/model/log.asp
4. Monthly Mean Article (peer reviewed): What is a pilot or feasibility study? A review of current practice and editorial policy
Mubashir Arain, Michael Campbell, Cindy Cooper, Gillian Lancaster. What is a pilot or feasibility study? A review of current practice and editorial policy. BMC Medical Research Methodology. 2010;10(1):67. Abstract: "BACKGROUND: In 2004, a review of pilot studies published in seven major medical journals during 2000-01 recommended that the statistical analysis of such studies should be either mainly descriptive or focus on sample size estimation, while results from hypothesis testing must be interpreted with caution. We revisited these journals to see whether the subsequent recommendations have changed the practice of reporting pilot studies. We also conducted a survey to identify the methodological components in registered research studies which are described as 'pilot' or 'feasibility' studies. We extended this survey to grant-awarding bodies and editors of medical journals to discover their policies regarding the function and reporting of pilot studies. METHODS: Papers from 2007-08 in seven medical journals were screened to retrieve published pilot studies. Reports of registered and completed studies on the UK Clinical Research Network (UKCRN) Portfolio database were retrieved and scrutinized. Guidance on the conduct and reporting of pilot studies was retrieved from the websites of three grant giving bodies and seven journal editors were canvassed. RESULTS: 54 pilot or feasibility studies published in 2007-8 were found, of which 26 (48%) were pilot studies of interventions and the remainder feasibility studies. The majority incorporated hypothesis-testing (81%), a control arm (69%) and a randomization procedure (62%). Most (81%) pointed towards the need for further research. Only 8 out of 90 pilot studies identified by the earlier review led to subsequent main studies. Twelve studies which were interventional pilot/feasibility studies and which included testing of some component of the research process were identified through the UKCRN Portfolio database. There was no clear distinction in use of the terms 'pilot' and 'feasibility'. Five journal editors replied to our entreaty. In general they were loathe to publish studies described as 'pilot'. CONCLUSION: Pilot studies are still poorly reported, with inappropriate emphasis on hypothesis-testing. Authors should be aware of the different requirements of pilot studies, feasibility studies and main studies and report them appropriately. Authors should be explicit as to the purpose of a pilot study. The definitions of feasibility and pilot studies vary and we make proposals here to clarify terminology." [Accessed October 25, 2010]. Available at: http://www.biomedcentral.com/1471-2288/10/67.
5. Monthly Mean Article (popular press): Lies, Damned Lies, and Medical Science
David H. Freedman. Lies, Damned Lies, and Medical Science. The Atlantic. 2010. Excerpt: "Much of what medical researchers conclude in their studies is misleading, exaggerated, or flat-out wrong. So why are doctors�to a striking extent�still drawing upon misinformation in their everyday practice? Dr. John Ioannidis has spent his career challenging his peers by exposing their bad science." [Accessed October 19, 2010]. Available at: http://www.theatlantic.com/magazine/archive/2010/11/lies-damned-lies-and-medical-science/8269/.
6. Monthly Mean Book: The Immortal Life of Henrietta Lacks
Rebecca Skloot. The Immortal Life of Henrietta Lacks. First Edition. Crown; 2010. Description: I got this book out of a sense of obligation. It sounded like a book that would be a bore to read, but something important enough that it would be worth reading anyway. I was wrong. The story was quite compelling. There were five stories, actually. The first is the story about the life of Henrietta Lacks, a young woman and mother of five children who died at a young age from a very aggressive cervical cancer. The second is the story of a cell line derived from the biopsy of this woman's tumor, taken without her permission or knowledge. This cell line, known as HeLa, was the first immortal human cell line developed. The HeLa cells played a unique role in much of the work involving development of the polio vaccine and in many other scientific developments over the past five decades. The third story is about the people in the laboratory that developed the HeLa cell line and what they did differently from other scientists at the time that helped develop the HeLa cell line. The fourth story is about the surviving children of Henrietta Lacks, how they were abused and taken advantage of by the same scientists that took Henrietta Lack's tumor sample without her knowledge, and how they dealt with the anger over this abuse. The fifth story is about how the author, Rebecca Skloot, worked to gain the trust of the Lacks family, who were justifiably anxious about strangers showing up and asking lots of questions. These stories are masterfully interwoven to illustrate their interdependence.
7. Monthly Mean Definition: What is the number needed to treat?
The number needed to treat (NNT) is a statistic that provides a practical interpretation of the effectiveness of a new treatment versus a standardized treatment. It is the estimated average number of patients that a doctor would need to treat in order to have one additional event occur. A small value means that a doctor will see a lot of events in very little time. A large value means that the doctor can treat a large number of patients while seeing only very few events.
When you are measuring an increase in bad events like side effects that might be associated with a treatment, then the number needed to treat is sometimes described as the number needed to harm (NNH). Often you can quantify the tradeoffs between the benefits and side effects of a treatment by comparing the NNT and NNH values.
You calculate NNT by taking the difference between the event probability in the treatment group and the event probability in the control group and inverting it (dividing it into 1). Suppose that a new drug cured 45% of the patients and a standard drug cured only 25%. The difference is 20% (0.2 or 1/5). Invert this difference to get 5. You would need to treat 5 patients, on average, in order to see one extra cure for the new drug compared to the standard drug.
Here are some examples of Numbers Needed to Treat, found at the Bandolier web site (http://www.jr2.ox.ac.uk/bandolier/index.html).
* Prevention of post-operative vomiting using Droperidol, NNT=4.4. For every four or five surgery patients treated with Droperidol, you will see one less vomiting incident on average.
* Prevention of infection from dog bites using antibiotics, NNT=16. For every 16 dog bites treated with antibiotics, you would see one fewer infection on average.
* Primary prevention of stroke using a daily low dose of aspirin for one year, NNT=102. For every hundred patient years of treatment with aspirin, you will see one fewer stroke on average.Notice that this last event is a rate. Assuming that the rates are reasonably homogenous over time, one hundred patient years is equivalent to following ten patients for a decade. Be careful, of course, of rates that are not homogenous over time. If the rates decline the longer you follow your patients, then the number of events you will see for one hundred patients during their first year of therapy would be quite different from the number of events you would see following ten patients for their first decade of therapy.
As mentioned above, the comparison of NNT and NNH is often instructive. Here is an example. A recently published article on the flu vaccine showed that among the children who received a placebo, 17.9% later had culture confirmed influenza. In the vaccine group, the rate was only 1.3%. This is a 16.6% absolute difference. When you invert this percentage, you get NNT=6. This means that for every six kids who get the vaccine, you will see one less case of flu on average.
The study also looked at the rate of side effects. In the vaccine group, 1.9% developed a fever. Only 0.8% of the controls developed a fever. This is an absolute difference of 1.1%. When you invert this percentage, you get NNH=90. This means that for every 90 kids who get the vaccine, you will see one additional fever on average.
For this study, NNH / NNT = 90 / 6 = 15. This tells you that you should expect to see one additional fever for every fifteen cases of flu prevented. Although I am not a medical expert, the vaccine looks very promising because you can prevent a lot of flu events and only have to put up with a few additional fevers. In general, it takes medical judgment to assess the trade-offs between the benefits of a treatment and its side effects. The NNT and NNH calculations allow you to assess these trade-offs.
This definition was updated from a page on my old website:
* http://www.childrens-mercy.org/stats/ask/nnt.asp
8. Monthly Mean Quote: All who drink of this remedy...
Here�s a quote from the Greek physician Galen (c. 130-210 A.D.) All who drink of this remedy recover in a short time, except those whom it does not help, who all die. Therefore, it is obvious that it fails only in incurable cases. As quoted at www.johndcook.com/blog/2008/04/15/galen-and-clinical-trials/
9. Monthly Mean Unsung Hero Award: John Hall
John Hall has a website about social survey research, Journeys in Survey Research,
* http://surveyresearch.weebly.com
and is a regular contributor to the SPSS email discussion group. His website includes has a very nice series of SPSS tutorials covering the various phases of research from data entry to simple descriptive statistics and hypothesis testing.
10. Monthly Mean Website: Advice on designing scientific posters
Advice on designing scientific posters. Colin Purrington. Description: Good practical advice, especially for beginners like me, on how to design and present a scientific poster. URL: www.swarthmore.edu/NatSci/cpurrin1/posteradvice.htm
11. Nick News: Nicholas the arachnologist
Nicholas, Cathy, and Steve went on an overnight cub scout camp. Part of the activities included a bug hunt. Nicholas caught an impressive spider.
It's inside a plastic box, so the image is not so clear. The body of the spider was about as big as the upper half of my thumb. I was told that this was a garden spider. It looks much too vicious to have such a sweet name. I would have called it a vampire spider or something else that would give the impression of how truly ferocious and dangerous this spider looked to me. Someone at work said "Oh those garden spiders make the prettiest webs." Again, this is not fitting with the image of the vicious beast that this creature truly is.
Nicholas also went fishing during the campout, but (thankfully) did not catch anything. Read more and see some additional pictures at
* http://www.pmean.com/personal/arachnologist.html
12. Very bad joke: A SQL query goes into a bar...
A SQL query goes into a bar, wanders up to two tables and asks "Can I join you?" http://stackoverflow.com/questions/17512/computer-language-puns-and-jokes
13. Tell me what you think.
How did you like this newsletter? I have three short open ended questions at
* https://app.icontact.com/icp/sub/survey/start?sid=6436&cid=338122You can also provide feedback by responding to this email. My three questions are:
* What was the most important thing that you learned in this newsletter?
* What was the one thing that you found confusing or difficult to follow?
* What other topics would you like to see covered in a future newsletter?Four people provided feedback to the last newsletter. The article on quality checks for data entry errors was appreciated, as was the "nuanced, non-prescriptive approach" to critiquing journal articles. There were no complaints about unclear or confusing items. There were suggestions about applications (and misapplications) of the generalized linear model, and on how to convey the uncertainty that biases cause in a research study.
14. Upcoming statistics webinars
I offer regular webinars (web seminars) for free as a service to the research community and to build up a bit of good will for my independent consulting business. Here are the next two webinars that I have scheduled.
The first three steps in designing a survey, Wednesday, November 17, 11am-noon, CST.
The first thee steps in obtaining ethical approval for your study, Thursday, December 16, 11am-noon, CST.
Both of these webinars represent chapters in an upcoming book that I'm hoping to get published. If you attend this webinar, I'd be very grateful for any comments and suggestions you might have.
To sign up for any of these webinars, send me an email with the date in the title line (e.g., "November 17 webinar"). For further information, go to
* http://www.pmean.com/webinars
15. Join me on Facebook and LinkedIn
I'm just getting started with Facebook and LinkedIn. My personal page on Facebook is
* www.facebook.com/pmeanand there is a fan page for The Monthly Mean
* www.facebook.com/group.php?gid=302778306676I usually put technical stuff on the Monthly Mean fan page and personal stuff on my page, but there's a bit of overlap.
My page on LinkedIn is
* www.linkedin.com/in/pmeanIf you'd like to be a friend on Facebook or a connection on LinkedIn, I'd love to add you.
What now?
Sign up for the Monthly Mean newsletter
Review the archive of Monthly Mean newsletters
![]() This work is licensed under a
Creative
Commons Attribution 3.0 United States License. This page was written by
Steve Simon and was last modified on
2017-06-15. Need more
information? I have a page with general help
resources. You can also browse for pages similar to this one at
Category: Website details.
This work is licensed under a
Creative
Commons Attribution 3.0 United States License. This page was written by
Steve Simon and was last modified on
2017-06-15. Need more
information? I have a page with general help
resources. You can also browse for pages similar to this one at
Category: Website details.